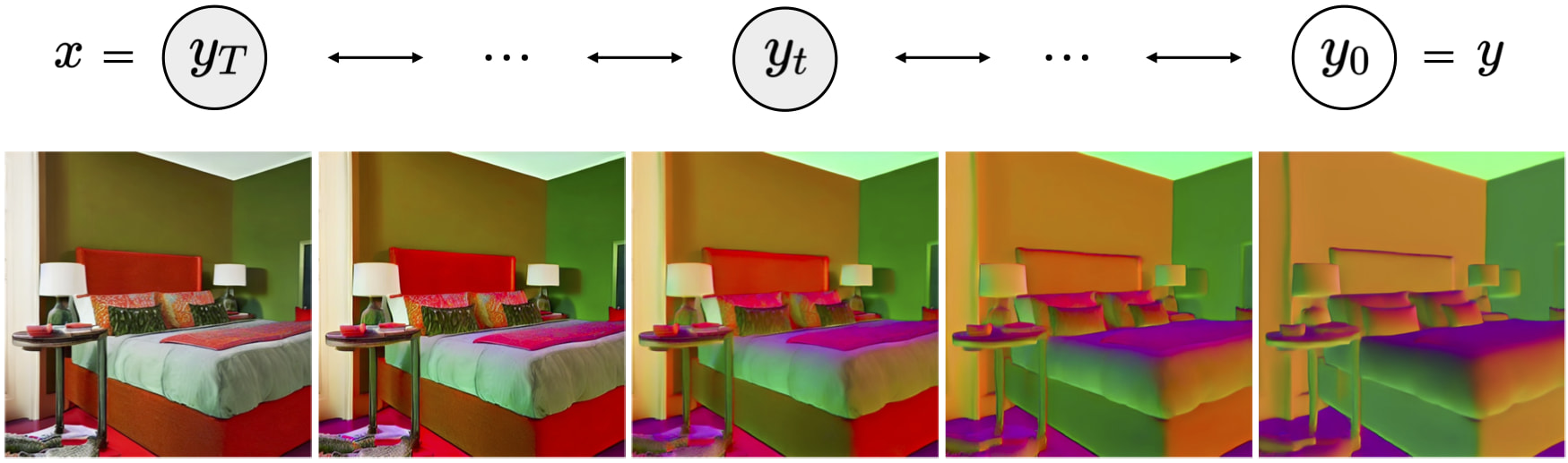
Surface Normals
imgs/demo/xl/8.jpg


imgs/demo/xl/18.jpg


imgs/demo/xl/20.jpg


imgs/demo/xl/23.jpg


imgs/demo/xl/27.jpg


imgs/demo/xl/28.jpg


imgs/demo/xl/30.jpg


imgs/demo/xl/31.jpg


imgs/demo/xl/32.jpg


imgs/demo/xl/33.jpg


Depth
imgs/demo/xl/2.jpg


imgs/demo/xl/4.jpg


imgs/demo/xl/8.jpg

imgs/demo/xl/12.jpg


imgs/demo/xl/17.jpg


imgs/demo/xl/18.jpg

imgs/demo/xl/23.jpg

imgs/demo/xl/28.jpg

imgs/demo/xl/31.jpg

imgs/demo/xl/33.jpg

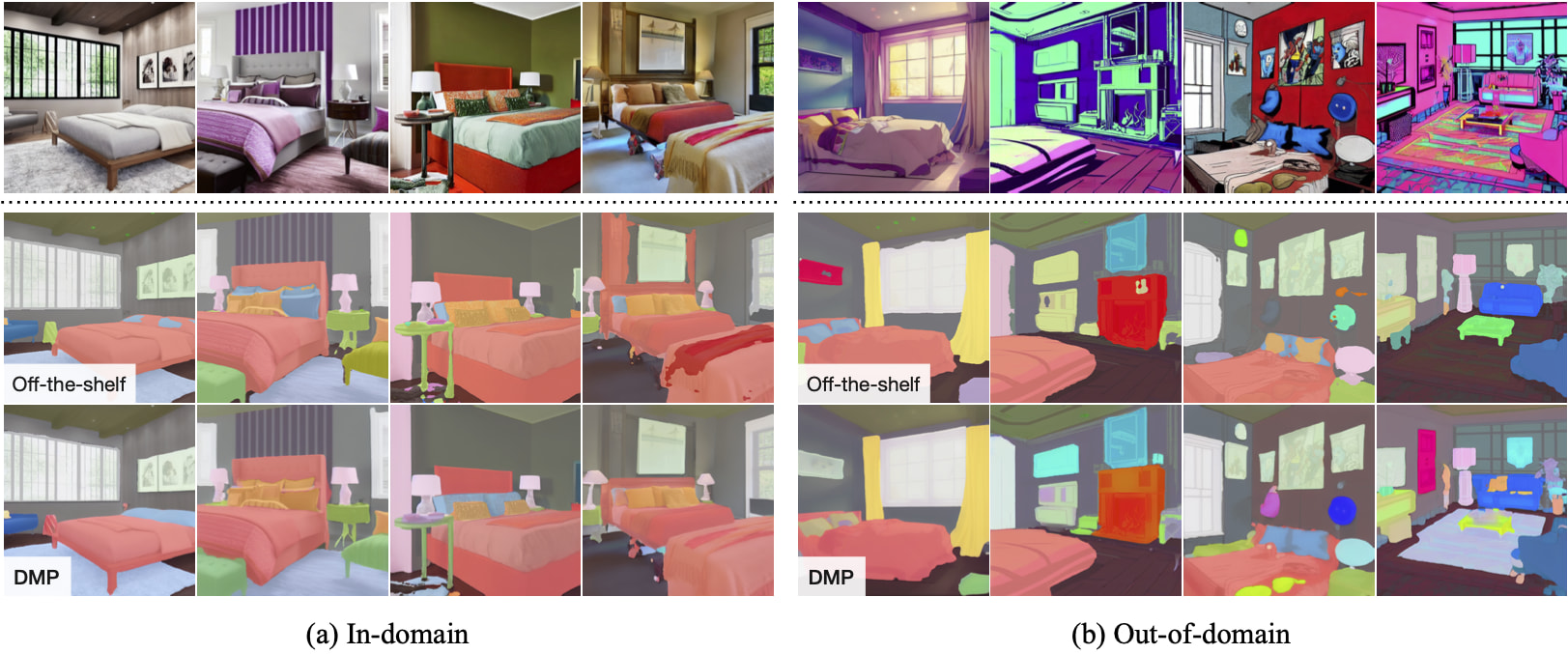
Semantic Segmentation
imgs/demo/xl/1.jpg


imgs/demo/xl/2.jpg


imgs/demo/xl/9.jpg


imgs/demo/xl/10.jpg


imgs/demo/xl/11.jpg


imgs/demo/xl/12.jpg


imgs/demo/xl/13.jpg


imgs/demo/xl/14.jpg


Albedo
imgs/demo/xl/1.jpg

imgs/demo/xl/2.jpg

imgs/demo/xl/3.jpg


imgs/demo/xl/4.jpg


imgs/demo/xl/5.jpg


imgs/demo/xl/6.jpg


imgs/demo/xl/7.jpg


imgs/demo/xl/8.jpg


Shading
imgs/demo/xl/1.jpg

imgs/demo/xl/2.jpg

imgs/demo/xl/3.jpg

imgs/demo/xl/4.jpg

imgs/demo/xl/5.jpg

imgs/demo/xl/6.jpg

imgs/demo/xl/7.jpg

imgs/demo/xl/8.jpg