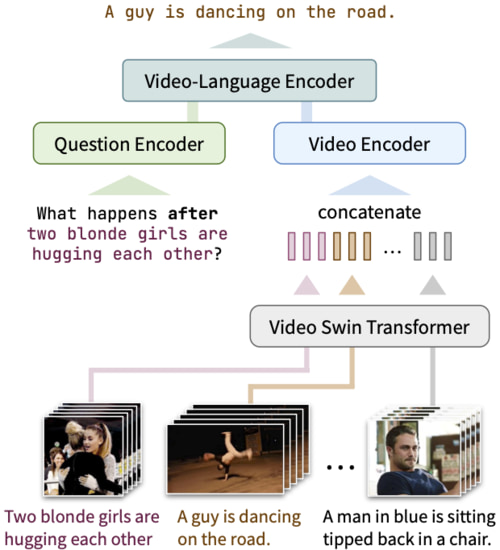
Home » PublicationsLearning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal ModelingNovember 21, 2022 · 0 min · 0 words · Me